Wer als Cloud-Architekt SLA-Gespräche mit internen Kunden führt, kennt das Problem: Es gibt eine Vereinbarung über 99.9% Verfügbarkeit, aber keine standardisierte Messung. Jedes Team baut eigene Dashboards, nutzt unterschiedliche KQL-Queries, und am Ende diskutiert man über Methodik statt über Ergebnisse.
Azure Monitor schließt diese Lücke jetzt mit Service Level Indicators (SLI) und Service Level Objectives (SLO) – ab sofort als Public Preview verfügbar. In diesem Artikel schaue ich mir an, was das Feature kann, wo die Grenzen liegen, und wie ihr es konkret einsetzt.
Warum jetzt? Der Kontext
Die Ankündigung kommt nicht im Vakuum. In den letzten Monaten hat Microsoft das Azure Monitor-Portfolio systematisch ausgebaut: Azure Monitor Pipeline (GA seit April 2026) für skalierbare Telemetrie-Ingestion, Azure SRE Agent für KI-gestützte Alert-Triage, und jetzt SLI/SLO für standardisierte Qualitätsmessung. Zusammen ergibt das ein Bild: Microsoft will Azure Monitor als vollständige Observability-Plattform positionieren – nicht nur für Metriken und Logs, sondern auch für Service Level Management, das bisher Drittanbietern vorbehalten war.
Für Teams , die bisher Datadog oder Nobl9 evaluiert haben, ändert sich die Kalkulation: Wenn die Kernfunktionalität nativ in Azure verfügbar ist, sinkt die Rechtfertigung für zusätzliche Tool-Kosten erheblich.
Was SLI/SLO löst – und was nicht
Zuerst die Einordnung: SLI/SLO ist kein neues Monitoring-Tool. Es ist eine Abstraktionsschicht über euren bestehenden Metriken und Logs, die eine standardisierte Antwort auf die Frage liefert: „Wie gut funktioniert mein Service aus Kundenperspektive?“
Das Konzept stammt aus dem Google SRE-Playbook und hat sich in den letzten Jahren von einem Nischenthema für Hyperscaler zu einem Standard-Werkzeug für jede Organisation entwickelt, die zuverlässige Cloud-Services betreibt. Azure Monitor übersetzt das Konzept in drei Ebenen:
SLI (Service Level Indicator): Eine quantitative Messung der Servicequalität. Beispiel: „Anteil der HTTP-Requests mit Statuscode < 500“ oder „Anteil der Requests mit Latenz < 200ms“.
SLO (Service Level Objective): Das Ziel für den SLI über einen Zeitraum. Beispiel: „99.9% Availability über 30 Tage“.
Error Budget: Die Differenz zwischen 100% und dem SLO-Ziel – also der Raum für erlaubte Fehler. Bei 99.9% SLO sind das 43.2 Minuten pro 30 Tage.
Was Azure Monitor SLI/SLO nicht löst: Es ersetzt keine APM-Tools, keine Distributed Tracing-Lösungen und keine Business-Metriken-Plattformen. Es gibt euch einen standardisierten Rahmen, um aus vorhandenen Daten die richtigen Schlüsse zu ziehen.
Die Architektur im Detail
Azure Monitor SLI/SLO integriert sich mit den Datenquellen, die ihr vermutlich bereits nutzt:
| Datenquelle | Unterstützte SLI-Typen | Typische Anwendung |
|---|---|---|
| Application Insights | Availability, Latency | Web-APIs, Frontend-Apps |
| Azure Monitor Metrics | Availability | VM Heartbeats, Load Balancer Probes |
| Log Analytics (KQL) | Custom SLIs | Business-spezifische Metriken |
| Azure Resource Health | Availability | Platform-Level Health |
Der entscheidende Punkt: Ihr braucht keine neuen Datenquellen einzurichten. Wenn eure Anwendung bereits Application Insights nutzt, habt ihr die Grundlage für SLI/SLO-Messungen.
Praktisches Setup: Schritt für Schritt
Bevor ihr ein SLO konfiguriert, braucht ihr Baseline-Daten. Die folgenden KQL-Queries liefern die Grundlage.
Schritt 1: Availability Baseline ermitteln
kql
// Verfügbarkeit der letzten 30 Tagerequests| where timestamp > ago(30d)| summarize TotalRequests = count(), SuccessfulRequests = countif(toint(resultCode) < 500), FailedRequests = countif(toint(resultCode) >= 500)| extend AvailabilityPct = round(100.0 * SuccessfulRequests / TotalRequests, 3)| project TotalRequests, SuccessfulRequests, FailedRequests, AvailabilityPct
Dieses Query zählt alle Requests mit HTTP-Statuscode >= 500 als Fehler. Das ist ein guter Startpunkt, aber ihr solltet die Definition an euren Service anpassen. Manche Teams zählen 429 (Too Many Requests) ebenfalls als Fehler, andere nicht.
Schritt 2: Latenz-Baseline prüfen
kql
// Latenz-Percentile der letzten 30 Tagerequests| where timestamp > ago(30d)| summarize P50 = percentile(duration, 50), P90 = percentile(duration, 90), P95 = percentile(duration, 95), P99 = percentile(duration, 99)| project P50_ms = round(P50, 1), P90_ms = round(P90, 1), P95_ms = round(P95, 1), P99_ms = round(P99, 1)
Schritt 3: Tägliche Verfügbarkeit visualisieren
kql
// Tägliche Availability - zeigt Muster und Ausreißerrequests| where timestamp > ago(30d)| summarize Total = count(), Success = countif(toint(resultCode) < 500) by bin(timestamp, 1d)| extend DailyAvailability = round(100.0 * Success / Total, 3)| project Day = format_datetime(timestamp, 'yyyy-MM-dd'), DailyAvailability, Total| order by Day asc
Diese Query zeigt euch, an welchen Tagen die Verfügbarkeit eingebrochen ist – und ob es Muster gibt (Deployments am Dienstag, Last am Freitagabend).
Schritt 4: SLO im Portal konfigurieren
In der aktuellen Preview erfolgt die Konfiguration über das Azure Portal:
- Navigiert zu Azure Monitor -> Service Level Objectives (Preview)
- Klickt auf „Create“
- Konfiguriert den SLI:
- Name: z.B.
api-availability-slo - SLI Type: Availability
- Data Source: Application Insights
- Good Events:
resultCode < 500 - Total Events: Alle Requests
- Name: z.B.
- Definiert das SLO:
- Target: 99.9%
- Evaluation Window: 30 Tage (rolling)
- Konfiguriert Alerts:
- Error Budget Alert: Trigger bei < 25% verbleibendem Budget
- Burn Rate Alert: Trigger bei Burn Rate > 10x Normal
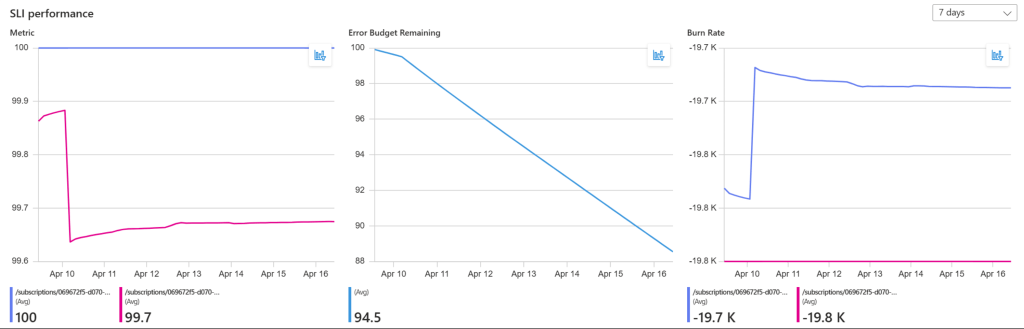
Error Budget als Steuerungsinstrument
Der eigentliche Mehrwert von SLI/SLO liegt nicht in der Messung selbst – sondern im Error Budget als Entscheidungsgrundlage.
Die Rechnung ist einfach:
SLO Target: 99.9%Error Budget: 0.1% = 43.2 Minuten pro 30 TageVerbrauch nach einer 15-Minuten-Störung:15 / 43.2 = 34.7% des Error Budgets verbraucht
Das Error Budget gibt euch ein objektives Kriterium für Entscheidungen, die sonst nach Bauchgefühl getroffen werden:
Error Budget > 50%: Freiraum für Feature-Releases und Infrastruktur-Änderungen. Das Team kann risikoreichere Deployments durchführen.
Error Budget 25-50%: Vorsichtiger operieren. Deployments nur mit soliden Rollback-Plänen, zusätzliches Testing vor Production.
Error Budget < 25%: Freeze für nicht-kritische Änderungen. Fokus auf Stabilisierung und Root Cause Analysis der bisherigen Incidents.
Error Budget aufgebraucht: Keine Deployments bis zum nächsten Evaluierungsfenster. Operations-Modus mit Fokus auf Incident Prevention.
Burn Rate Alerts ergänzen das Bild: Wenn die aktuelle Fehlerrate das Budget in weniger als 3 Tagen aufbrauchen würde, bekommt das Team eine sofortige Benachrichtigung – noch bevor das Budget tatsächlich erschöpft ist.
Das klingt theoretisch, hat aber in der Praxis einen massiven Effekt: Statt endloser Diskussionen in Change Advisory Boards gibt es eine objektive Zahl. „Wir haben noch 60% Error Budget – das Deployment geht durch“ oder „Budget ist bei 15% – wir verschieben auf nächste Woche“. Das nimmt Emotionen aus Entscheidungen, die sonst von der lautesten Stimme im Raum dominiert werden.
Vergleich: Azure Monitor SLI/SLO vs. Alternativen
Bisher mussten Azure-Teams auf externe Tools oder Eigenbauten ausweichen. Hier eine Einordnung:
| Kriterium | Azure Monitor SLI/SLO | Datadog SLOs | Nobl9 | Eigenbau (KQL) |
|---|---|---|---|---|
| Kosten | Preview: kostenlos | Ab $23/Host | Ab $500/Monat | Arbeitszeit |
| Integration | Nativ in Azure | Multi-Cloud | Multi-Cloud | Manuell |
| Setup-Aufwand | Gering (Portal) | Mittel | Hoch | Hoch |
| CLI/IaC Support | Noch nicht (Preview) | Ja | Ja | Ja (KQL Alerts) |
| Composite SLOs | Noch nicht | Ja | Ja | Manuell |
| Error Budget Alerts | Ja | Ja | Ja | Selbst bauen |
| Burn Rate Alerts | Ja | Ja | Ja | Selbst bauen |
| Historical Tracking | Ja | Ja | Ja | Manuell |
Der größte Vorteil von Azure Monitor SLI/SLO ist die native Integration – keine zusätzliche Datenquelle, kein Agent, kein Export. Der größte Nachteil in der Preview: Kein CLI- oder Bicep-Support, was Infrastructure-as-Code-Workflows einschränkt.
Einschränkungen und Stolperfallen
Ehrliche Einordnung der Grenzen in der aktuellen Preview:
- Nur Portal-Konfiguration: Kein
az monitor slo createBefehl, kein Bicep Resource, kein Terraform Provider Support. Für Teams, die alles als Code managen, ist das ein Blocker für produktive Nutzung - Keine Composite SLOs: Ein SLO kann nur einen SLI messen. „99.9% Availability UND P95 < 200ms“ erfordert zwei separate SLOs – nicht ideal für holistische Service-Bewertung
- Begrenzte Evaluation Windows: Die maximalen Zeiträume sind in der Preview eingeschränkt – Details in der Dokumentation
- Kein Export nach Azure DevOps: Automatische Work-Item-Erstellung bei SLO-Verletzung ist noch nicht möglich
- Pricing für GA unklar: In der Preview kostenlos, aber das GA-Preismodell ist noch nicht kommuniziert
SLI-Design: Die richtigen Metriken wählen
Ein häufiger Fehler beim Einstieg in SLI/SLO: Teams messen das Falsche. Die Verfügbarkeit eures Azure App Service ist nicht identisch mit der Verfügbarkeit, die eure Nutzer erleben. Ein Service kann laut Platform Metrics zu 100% verfügbar sein, während die Anwendung darauf 500er wirft.
Gute SLIs messen aus Nutzerperspektive. Konkret bedeutet das:
Availability SLI: Nicht „Server ist erreichbar“, sondern „Request wurde erfolgreich beantwortet“. Die Grenze liegt bei euch – typisch ist HTTP 5xx als Fehler, aber je nach API-Design können auch bestimmte 4xx-Codes relevant sein (etwa 408 Request Timeout).
Latency SLI: Nicht der Durchschnitt, sondern ein Percentil. P95 oder P99 sind üblich – weil der Durchschnitt Ausreißer versteckt. Wenn 1% eurer Nutzer 10 Sekunden warten, ist der Durchschnitt trotzdem „gut“. Das P99 zeigt die Wahrheit.
Wichtig: Startet mit wenigen SLOs. Ein Availability SLO und ein Latency SLO pro Service reichen. Mehr erzeugt nur Noise ohne zusätzlichen Erkenntnisgewinn.
Empfehlung: So startet ihr
Meine Empfehlung für den Einstieg:
Phase 1 (jetzt): Wählt eine unkritische Anwendung mit Application Insights. Konfiguriert ein Availability SLO mit 99.9% Target und 30-Tage-Window. Beobachtet 2-4 Wochen, ob die Messung eure Wahrnehmung der Servicequalität widerspiegelt.
Phase 2 (nach Baseline): Erweitert auf produktionskritische Services. Definiert Availability und Latency SLOs. Konfiguriert Error Budget und Burn Rate Alerts. Integriert die SLO-Ergebnisse in eure Operations-Reviews.
Phase 3 (nach GA): Sobald CLI/IaC-Support verfügbar ist, standardisiert die SLO-Konfiguration in euren Deployment-Pipelines. Jeder neue Service bekommt automatisch SLOs als Teil des Provisioning.
bash
# Quick Start: Application Insights Verfügbarkeit prüfenaz monitor app-insights component show \ --app myapp-appinsights \ --resource-group rg-prod \ --query "{Name:name, InstrumentationKey:instrumentationKey, IngestionMode:ingestionMode}" \ -o table# Prüfen, ob Requests geloggt werdenaz monitor app-insights query \ --app myapp-appinsights \ --resource-group rg-prod \ --analytics-query "requests | where timestamp > ago(1d) | count"
Fazit
Azure Monitor SLI/SLO ist kein revolutionäres Feature – das Konzept existiert seit Jahren im Google SRE-Playbook. Aber die native Integration in Azure Monitor macht es erstmals praktikabel für Teams, die bisher weder Budget noch Kapazität für dedizierte SLO-Plattformen hatten. Für IT-Leiter im Mittelstand ist das besonders relevant: Ihr könnt euren internen Kunden jetzt objektiv und nachvollziehbar zeigen, wie gut eure Cloud-Services performen – mit einem Tool, das bereits in eurem Azure-Abonnement enthalten ist.
Die Preview hat Lücken, besonders beim IaC-Support und bei Composite SLOs. Aber die Grundfunktionalität – SLI-Definition, SLO-Tracking, Error Budget Alerts und Burn Rate Detection – funktioniert bereits solide. Mein Rat: Nicht warten, bis GA kommt. Die Preview-Phase ist der beste Zeitpunkt, um das Konzept im Team zu etablieren, Baseline-Daten zu sammeln und erste Erfahrungen zu machen, bevor es produktionskritisch wird.
Dieser Artikel ist Teil des „Last Week in Azure & Tech“ Newsletters. Jede Woche die wichtigsten Azure-Updates, praxisnah aufbereitet: Newsletter abonnieren

Hinterlasse einen Kommentar